U-статистика Манна-Уитни. Ее связь с ROC-AUC и GINI
Содержание
В конце прошлого поста я оставил крючок к этой теме. Сегодня хочу подсветить связь между непараметрическими статистиками и привычными метриками качества классификации.
В моём случае осознание этой связи изменило отношение к этим метрикам. ROC-AUC и GINI – это не формулы, которые кто-то придумал и проверил на практике. За ними стоит U-статистика Манна-Уитни – один из фундаментальных инструментов непараметрической статистики. Метрики не взяты из головы. Они возникают естественно, из простого вопроса: как часто модель правильно ранжирует пару объектов?
Общий фундамент: U-статистика Манна-Уитни
В предыдущей статье мы разбирали ROC-AUC как долю правильно ранжированных пар. Напомню суть: берём все возможные пары (positive, negative), считаем, в скольких из них positive получил скор выше. Это число – U-статистика Манна-Уитни.
где – число positive, – число negative, – скор модели.
AUC и GINI – это две разные нормировки одной и той же величины :
Три представления одной статистики. – абсолютное число правильных пар. AUC – доля правильных пар. GINI – избыток правильных пар сверх случайного уровня, нормированный на максимум.
Визуально: что такое U
Вот конкретный пример. 4 positive-объекта, 5 negative-объектов. Каждая ячейка матрицы представляет одну пару. Зелёная – модель ранжировала правильно (positive выше), красная – ошибка.
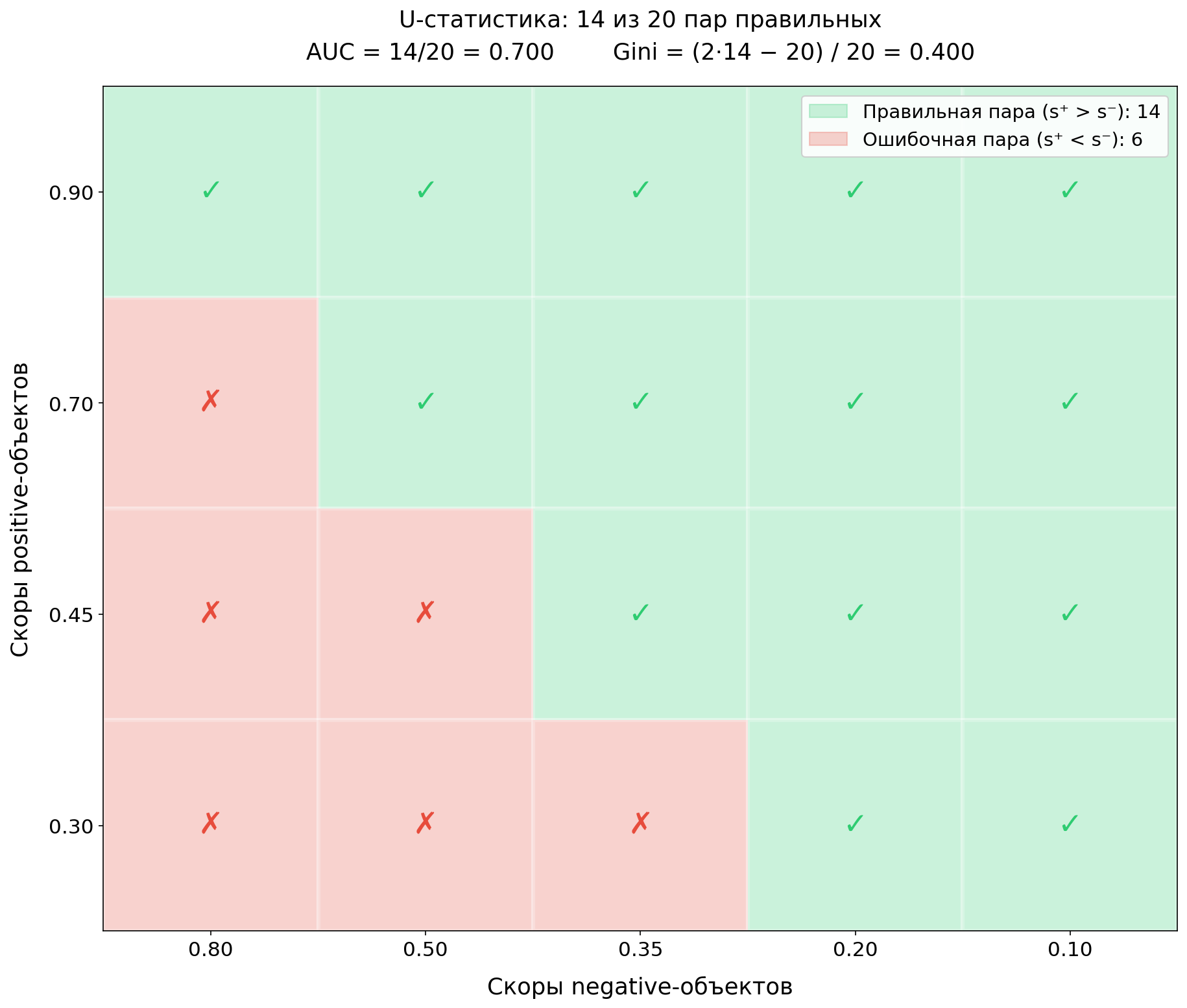
– просто число зелёных ячеек. AUC - доля зелёных. GINI – на сколько доля зелёных превышает 50% (случайный уровень), нормированная к единице.
Шкала – это не мелочь
Связь между AUC и GINI тривиальна:
Но я призываю вас к пониманию, что шкала – это очень важная история.
ROC-AUC живёт на отрезке [0, 1], но нижняя половина представляет собой мертвую зону. Модель с AUC = 0.5 случайно угадывает результат. На практике все рабочие значения лежат в диапазоне [0.5, 1.0]. Половина шкалы не используется.
Gini живёт на отрезке [0, 1], и вся шкала рабочая. GINI = 0 значит, что модель случайно угадывает. GINI = 1 значит, что модель обладает идеальной различающей способностью. Никаких мёртвых зон.
Различия между моделями виднее. Возьмём четыре модели:
| Модель | AUC | GINI |
|---|---|---|
| 1 | 0.81 | 0.62 |
| 2 | 0.84 | 0.68 |
| 3 | 0.87 | 0.74 |
| 4 | 0.90 | 0.80 |
В AUC разница между соседними моделями 3 п.п., а в GINI 6 п.п. Одна и та же информация, но GINI удваивает сигнал. Когда вы показываете результат менеджеру, «модель улучшилась с 0.62 до 0.74» звучит убедительнее, чем «с 0.81 до 0.87».
Казалось бы, ерунда, но порой это имеет ключевое значение. Да, вы провели крутую работу, сделали крутой анализ, показали классный результат, но, пренебрегая такой мелочью, вы рискуете не зафиксировать свой результат.
Непараметричность: что это значит и почему это козырь
И AUC, и GINI наследуют ключевое свойство U-статистики: они непараметрические. Это означает, что они не делают никаких предположений о распределении скоров модели. Не важно, нормальные они, экспоненциальные, бимодальные, с тяжёлыми хвостами.
Кстати, это означает, что любое монотонное преобразование скоров оставляет AUC и GINI неизменными. Если вы возьмите логарифм, возведите в куб, пропустите через сигмоиду, то ранги объектов не изменятся, а U-статистика считает только ранги.
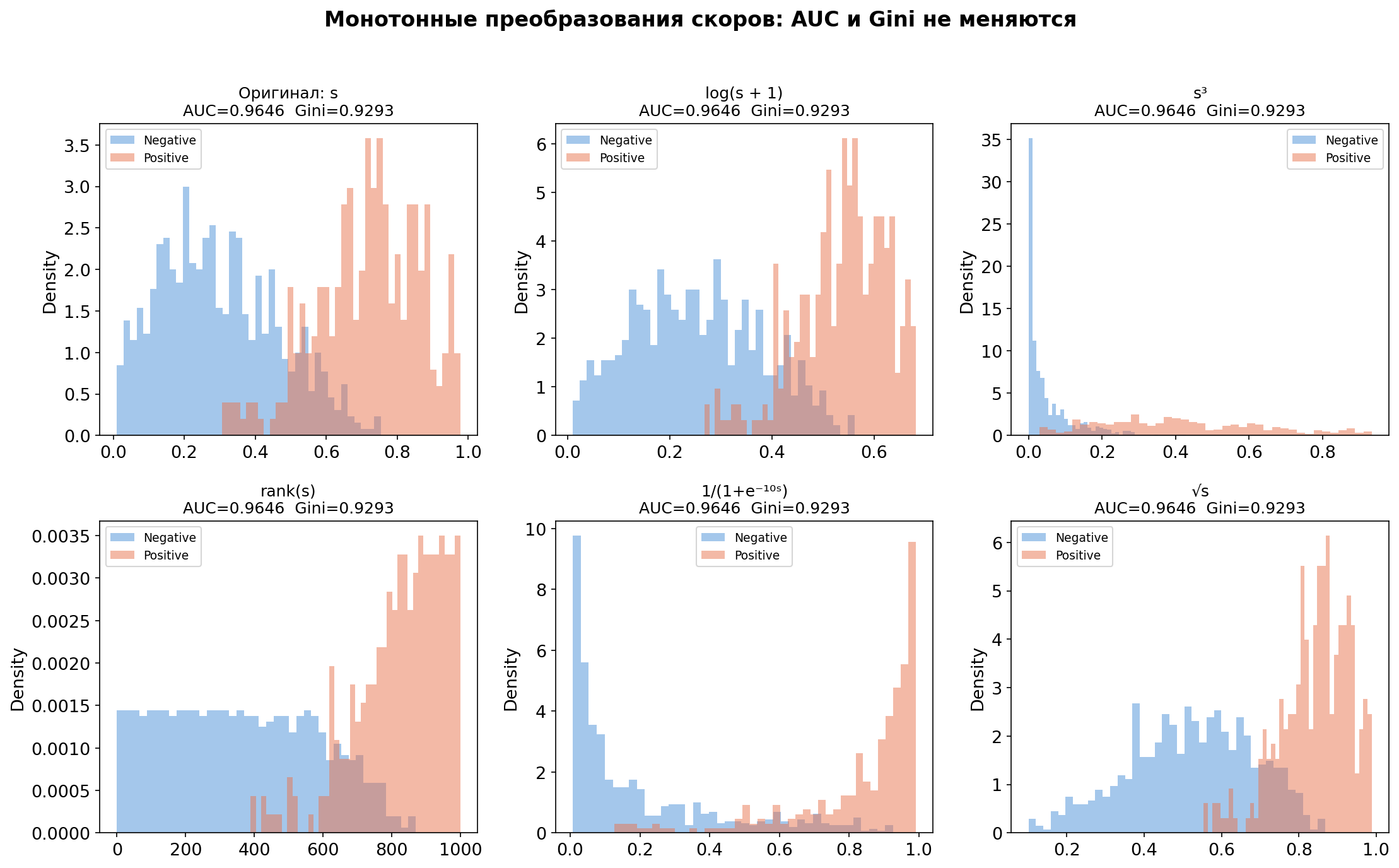
Шесть разных преобразований одних и тех же скоров. Распределения выглядят совершенно по-разному. AUC и GINI одинаковые.
А вот немонотонное преобразование (например, ) ломает порядок рангов и метрики меняются:
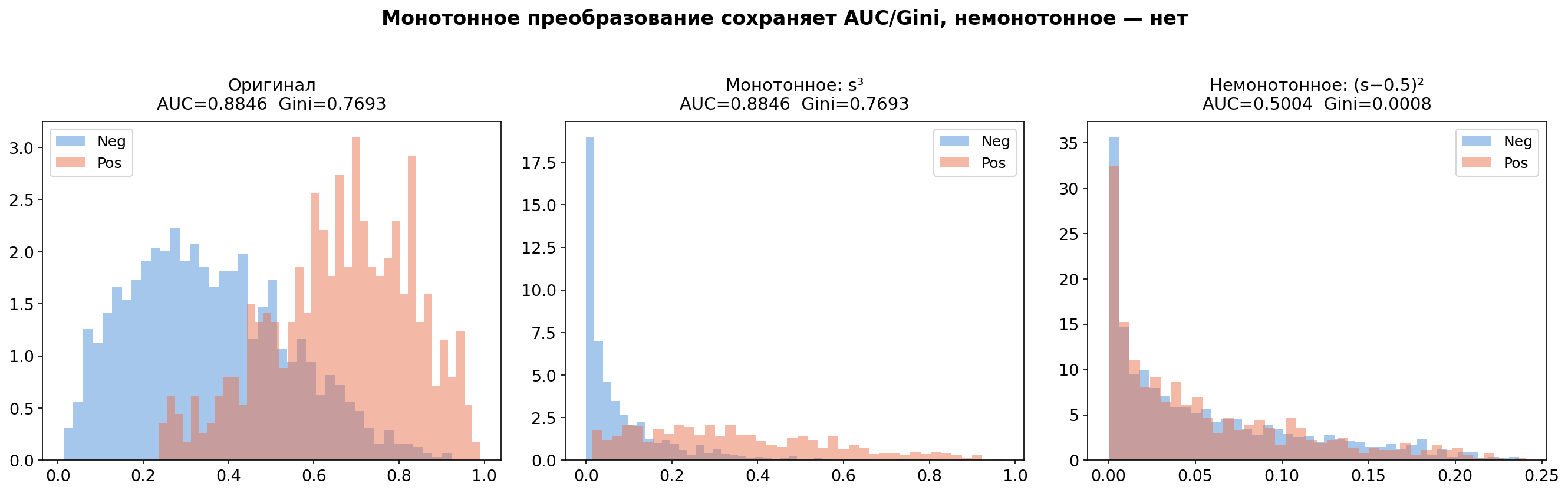
Это важно на практике: калибровка скоров (Platt scaling, isotonic regression) представляет собой монотонное преобразование, поэтому она не влияет на AUC/GINI. А вот ошибка в пайплайне, которая перемешивает ранги повлияет.
Кривая Лоренца: собственная визуализация GINI
У ROC-AUC есть ROC-кривая. У GINI есть кривая Лоренца (она же CAP-кривая в кредитном скоринге).
Построение: отсортируем объекты по убыванию скора модели. По оси X – доля просмотренных объектов, по оси Y – доля найденных positives. Диагональ – случайная модель. Чем выше кривая над диагональю, тем лучше модель концентрирует positives в топе.
GINI представляет собой отношение площади между кривой Лоренца и диагональю к площади между идеальной моделью и диагональю.
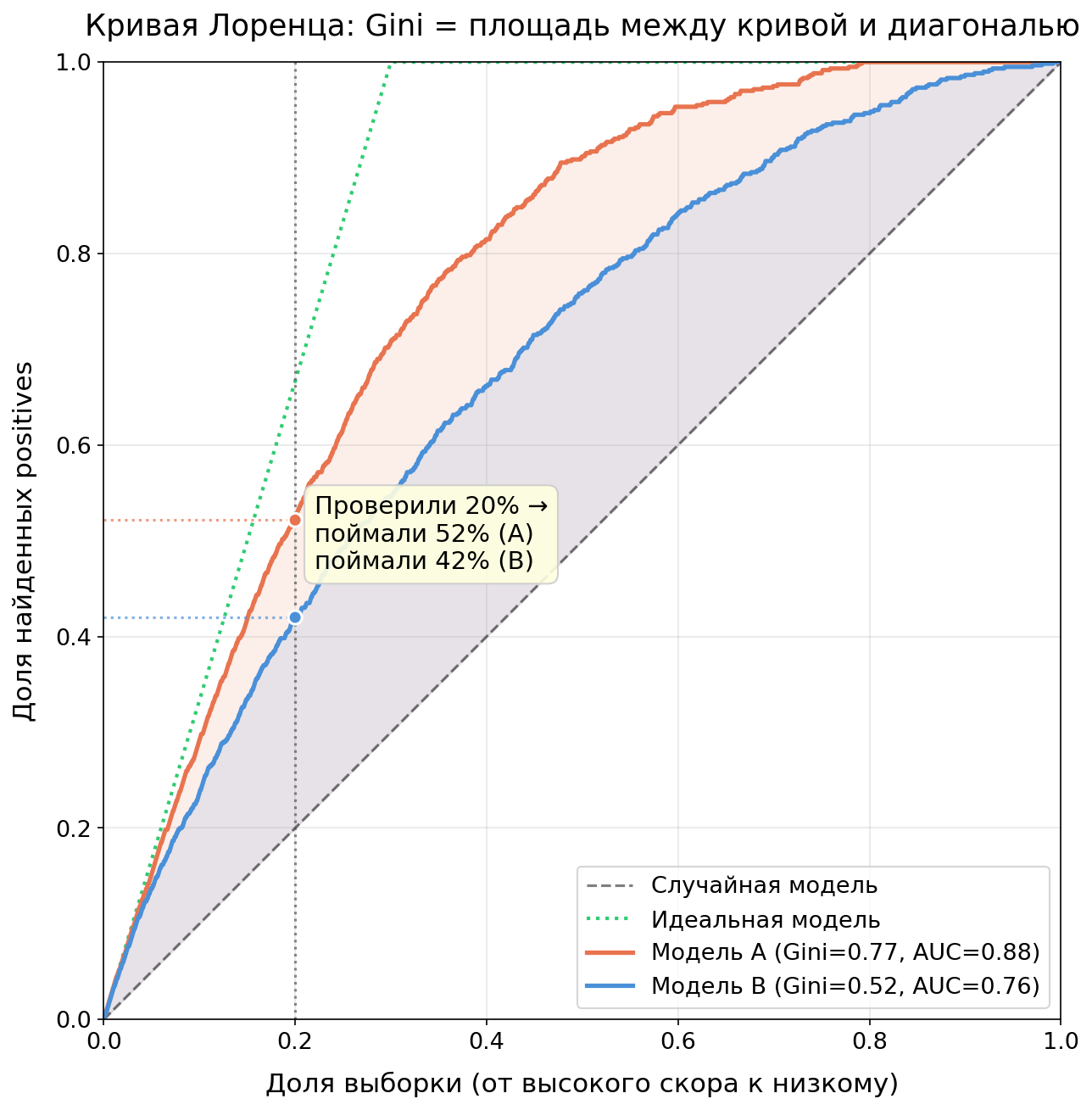
Кривая Лоренца отвечает на бизнес-вопрос напрямую: «Если мы проверим топ-K% клиентов по скору, какую долю дефолтов мы поймаем?». Просто ищите K на оси X и сопоставляйте ему значение на оси Y. ROC-кривая отвечает на этот вопрос косвенно, через TPR и FPR.
ROC vs Лоренц
Одни и те же две модели, визуализированные обоими способами:
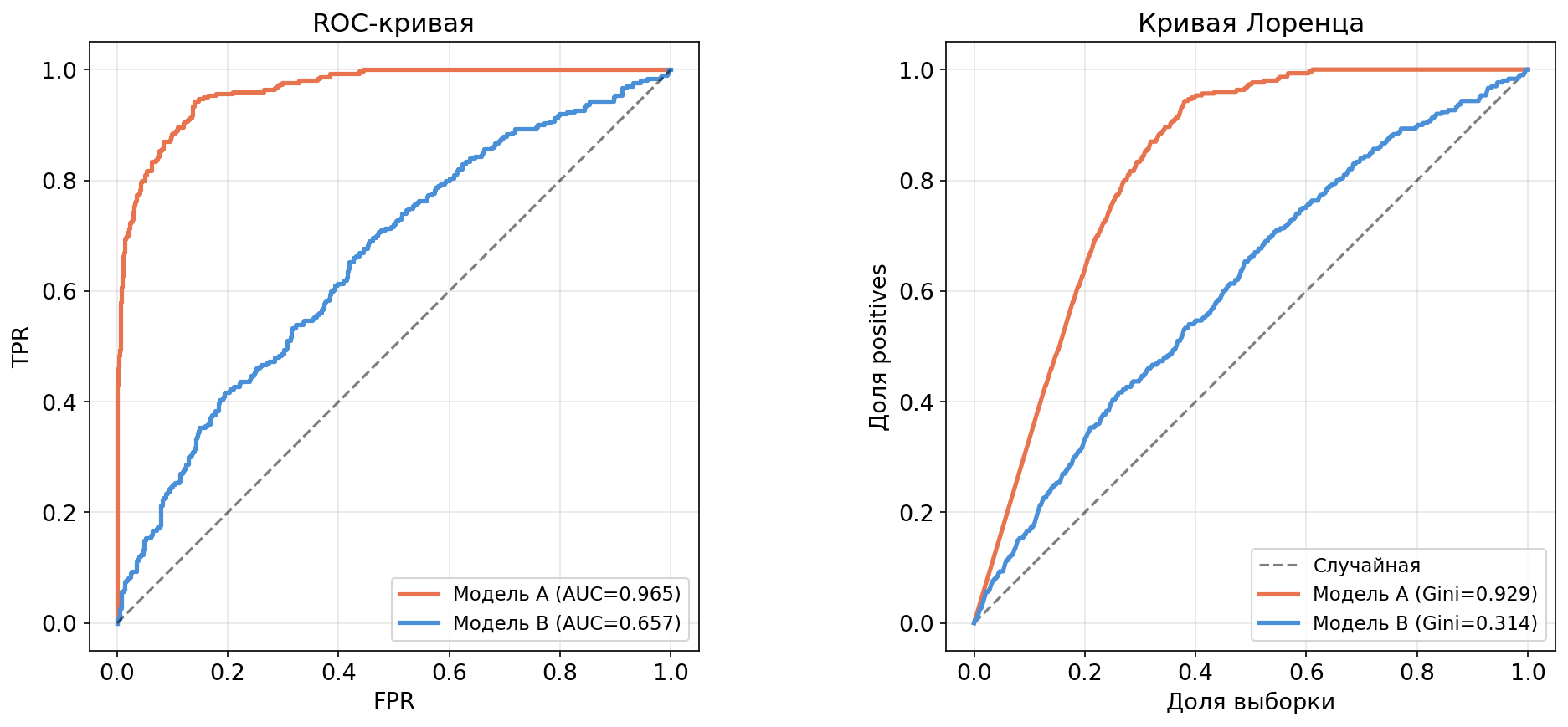
Обе визуализации показывают, что модель A лучше модели B. Но на кривой Лоренца разница между моделями визуально более выражена — площадь между кривыми читается нагляднее.
Где GINI — стандарт индустрии
В банковском скоринге, страховании и риск-менеджменте Gini coefficient - основная метрика. Не ROC-AUC. Причины исторические и практические.
Скоринговые модели оцениваются регуляторами, аудиторами, бизнесом. Всем нужна шкала, где 0 = бесполезная модель и 1 = идеальная. Gini это даёт. AUC — нет.
Типичные бенчмарки в индустрии: GINI > 0.4 — приемлемая модель, GINI > 0.6 — хорошая, GINI > 0.8 — отличная. Эти пороги читаются интуитивно. Попробуйте перевести их в AUC (> 0.7, > 0.8, > 0.9) — формально то же самое, но восприятие другое.
Итого: козыри GINI
Вся шкала рабочая. 0 — случайная модель, 1 — идеальная. Никаких мёртвых зон.
Разница между моделями виднее. Удвоенный масштаб различий по сравнению с AUC.
Кривая Лоренца. Отвечает на бизнес-вопрос напрямую — «сколько поймаем, если проверим топ-N%?».
Непараметричность. Через U-статистику работает без предположений о распределении, инвариантен к монотонным преобразованиям скоров.
Интерпретация через пары. «Модель правильно ранжирует 70% пар сверх случайного уровня» (GINI = 0.7) — прозрачнее, чем «AUC = 0.85».
Как генерировались данные для визуализаций
Все графики в статье построены на одном синтетическом датасете. 2000 объектов: 600 positive и 1400 negative. Скоры моделей сгенерированы из Beta-распределений — они удобны тем, что живут на отрезке [0, 1] и позволяют легко контролировать степень пересечения классов.
import numpy as np
from sklearn.metrics import roc_auc_score
np.random.seed(42)
n = 2000
y_true = np.array([1] * 600 + [0] * 1400)
#Модель A - хорошее разделение
scores_A = np.where(y_true == 1,
np.random.beta(4, 2, n),
np.random.beta(2, 3.5, n))
#Модель B - слабое разделение
scores_B = np.where(y_true == 1,
np.random.beta(3, 2, n),
np.random.beta(2, 3, n))
print("Модель A: AUC=" + str(round(roc_auc_score(y_true, scores_A), 3)))
print("Модель B: AUC=" + str(round(roc_auc_score(y_true, scores_B), 3)))
Результат:
Модель A: AUC=0.885, Gini=0.769
Модель B: AUC=0.762, Gini=0.524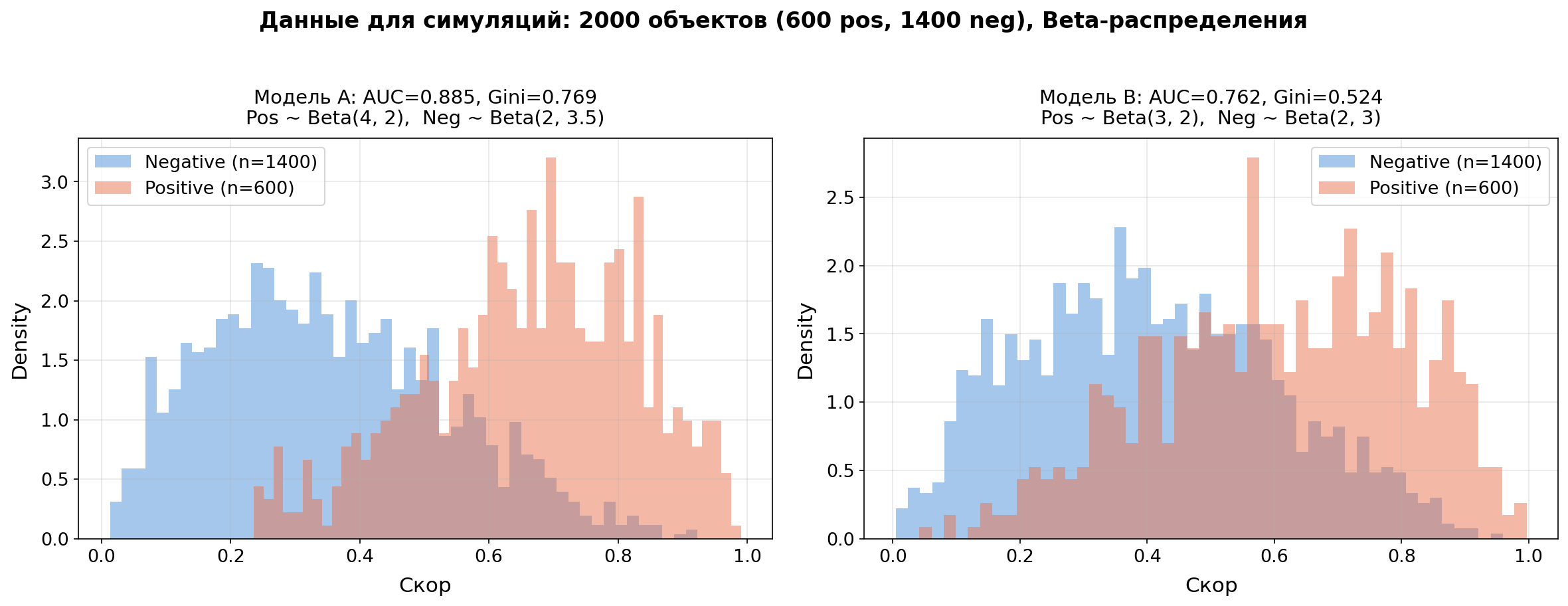
Логика простая: для positive-объектов берём Beta с перевесом вправо (высокие скоры), для negative - с перевесом влево. Чем сильнее различаются параметры, тем лучше модель разделяет классы.