Энтропия, Information Gain и Cross-Entropy: одна формула
Содержание
Сегодня мы разберём всё, что связано с энтропией. Долгое время я относился к ней как к «мере неопределённости». Но если отследить историю появления энтропии от задачи Шеннона про передачу сообщений по проводу до Information Gain в деревьях и cross-entropy loss в нейросетях, то можно качественно уловить связь между вещами, которые на первый взгляд не имеют ничего общего. То есть, конечно, определение через «меру неопределённости» верно, но не передает полноценно смысл.
Когда XGBoost выбирает сплит и когда нейросеть обновляет веса, они делают одно и то же: минимизируют неопределённость. Под капотом обоих — формула, которую Клод Шеннон написал в 1948 году для совсем другой задачи: как эффективно передавать сообщения по проводу.
Сегодня разберём, как одна формула связывает три мира: теорию информации, деревья решений и нейросети.
Энтропия Шеннона: сколько бит нужно?
Забудьте определение «энтропия – мера хаоса». Начнём с задачи.
У вас есть случайная величина, и вы хотите передать её значение кому-то. Сколько бит вам потребуется?
Монетка (честная). Два исхода, равновероятных. Нужен 1 бит: 0 – орёл, 1 – решка.
Кубик (честный). Шесть исходов. Нужно бит.
Кубик, который всегда падает на 6. Один исход. Нужно 0 бит – получатель и так знает ответ.
Закономерность: чем предсказуемее исход, тем меньше информации он несёт. Шеннон формализовал это в одной формуле:
где — вероятность -го исхода.
Проверим:
- Честная монетка: бит ✓
- Честный кубик: бит ✓
- Кубик-шестёрка: бит ✓
Для бинарной классификации (два класса с вероятностями и ) энтропия принимает вид:
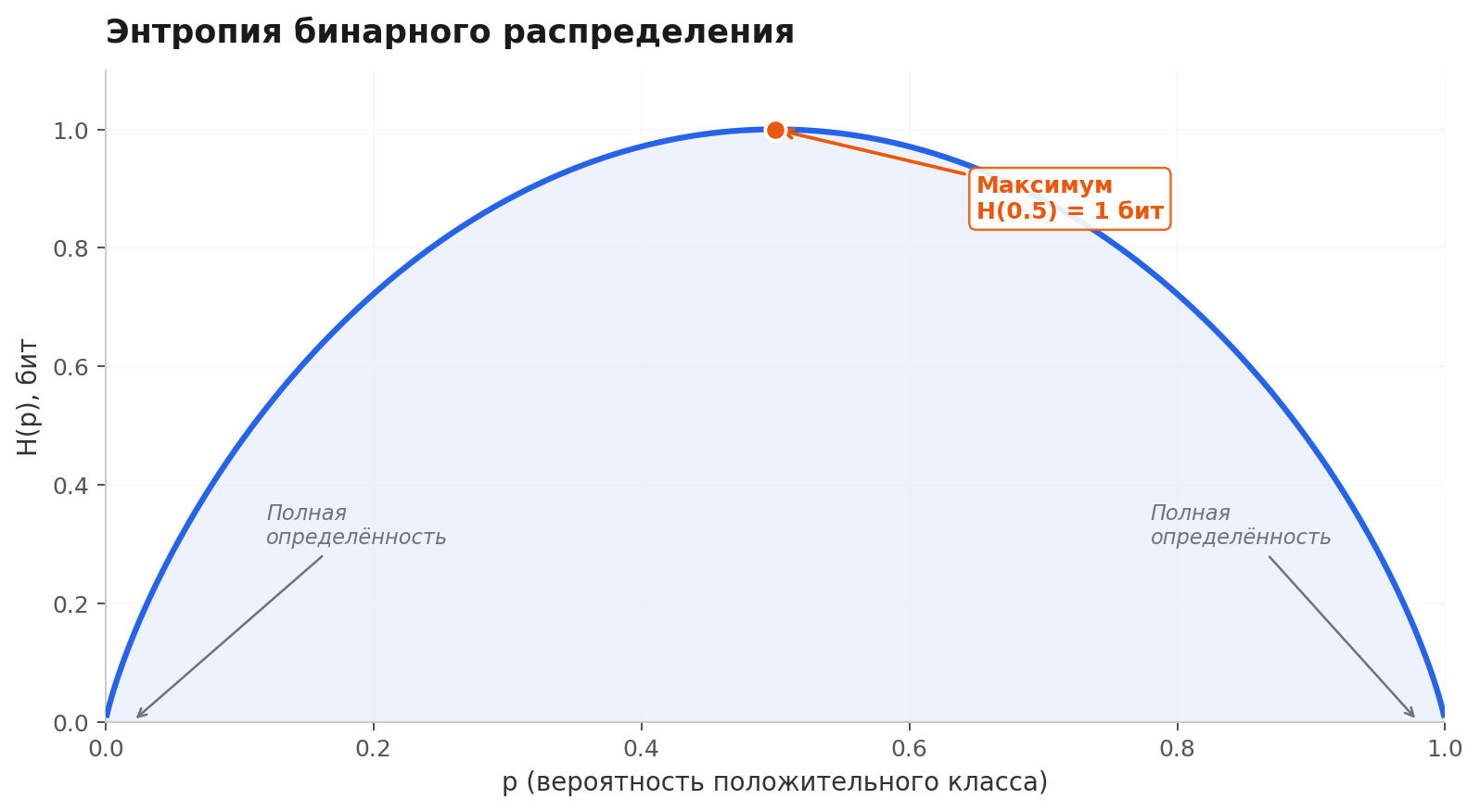
Максимум в . Минимумы в и представляют собой полную определенность. Эта кривая — фундамент всего, что будет дальше.
Information Gain: как деревья выбирают сплит
Дерево решений на каждом шаге решает: по какому признаку и по какому порогу разрезать данные? Критерий Information Gain: насколько сплит снижает неопределённость.
где — подмножества после сплита, их доли.
Конкретный пример
100 объектов: 60 положительных, 40 отрицательных. Энтропия до сплита:
Сплит A делит на две группы:
- Левая: 50 объектов (45 положительных, 5 отрицательных) →
- Правая: 50 объектов (15 положительных, 35 отрицательных) →
Сплит B делит на две группы:
- Левая: 50 объектов (35 положительных, 15 отрицательных) →
- Правая: 50 объектов (25 положительных, 25 отрицательных) →
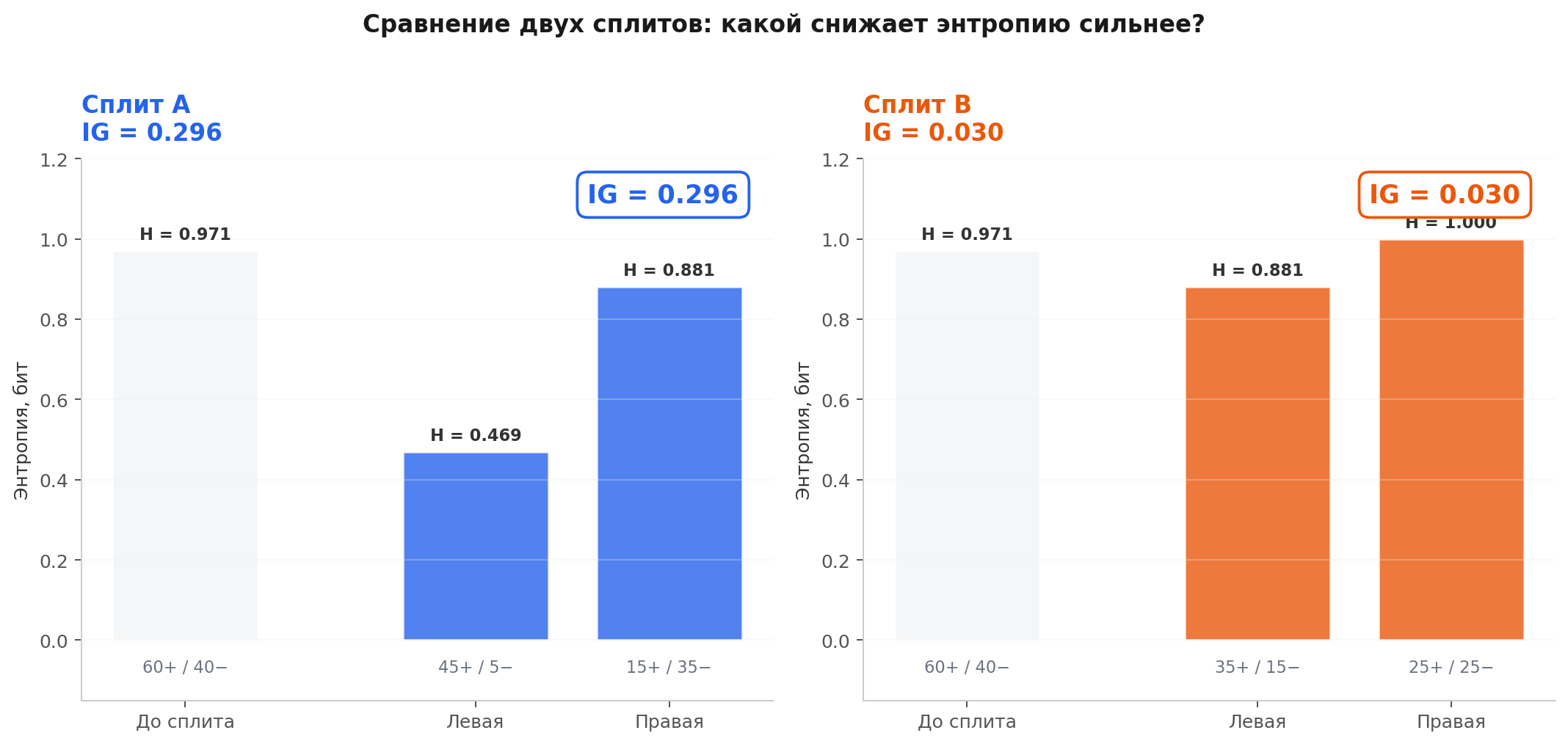
Сплит A даёт Information Gain в 10 раз больше. Дерево выберет его, потому что он сильнее снижает неопределённость. Левая ветка после сплита A почти чистая (90% положительных), правая тоже относительно определённая (70% отрицательных). Сплит B почти не помог: правая ветка – чистый хаос (50/50).
Когда XGBoost перебирает тысячи признаков и порогов, он ищет максимум Information Gain. Он ищет разрез, который превращает неопределённость в определённость. Это оптимизация энтропии.
KL-дивергенция: расстояние между распределениями
До сих пор мы измеряли неопределённость одного распределения. Теперь давайте измерим, насколько одно распределение отличается от другого.
Представьте: истинное распределение , а вы его аппроксимируете распределением . Если вы используете код, оптимальный для , для передачи данных из , вы потратите лишние биты. Сколько именно лишних?
Свойства:
- всегда
- только когда
- Не симметрична:
KL-дивергенция это не расстояние в строгом смысле (нет симметрии), но она измеряет «информационную стоимость» ошибки: сколько бит вы теряете, используя неправильную модель.
Cross-Entropy Loss: откуда берётся функция потерь
Теперь ключевое соединение. Cross-entropy между и определяется как:
И она разлагается на два компонента:
Cross-entropy = энтропия истинного распределения + KL-дивергенция.
Когда мы обучаем нейросеть, — это истинные метки (one-hot вектор), — предсказания модели. Энтропия для one-hot меток равна нулю (нет неопределённости, мы точно знаем класс). Значит:
Минимизировать cross-entropy loss = минимизировать KL-дивергенцию = приближать предсказания модели к реальности.
Для бинарной классификации формула принимает знакомый вид:
где — истинная метка, — предсказанная вероятность.
Это та же энтропия Шеннона, только теперь не «сколько бит нужно», а «сколько бит мы тратим зря из-за того, что модель ошибается».
Когда нейросеть обучается с cross-entropy loss, она буквально учится кодировать реальность с минимальным количеством лишних бит.
Замыкаем круг
Три мира, одна идея:
| Контекст | Вопрос | Формула |
|---|---|---|
| Теория информации | Сколько бит нужно для кодирования? | |
| Деревья решений | Какой сплит снижает неопределённость? | |
| Нейросети | Как далеки предсказания от реальности? |
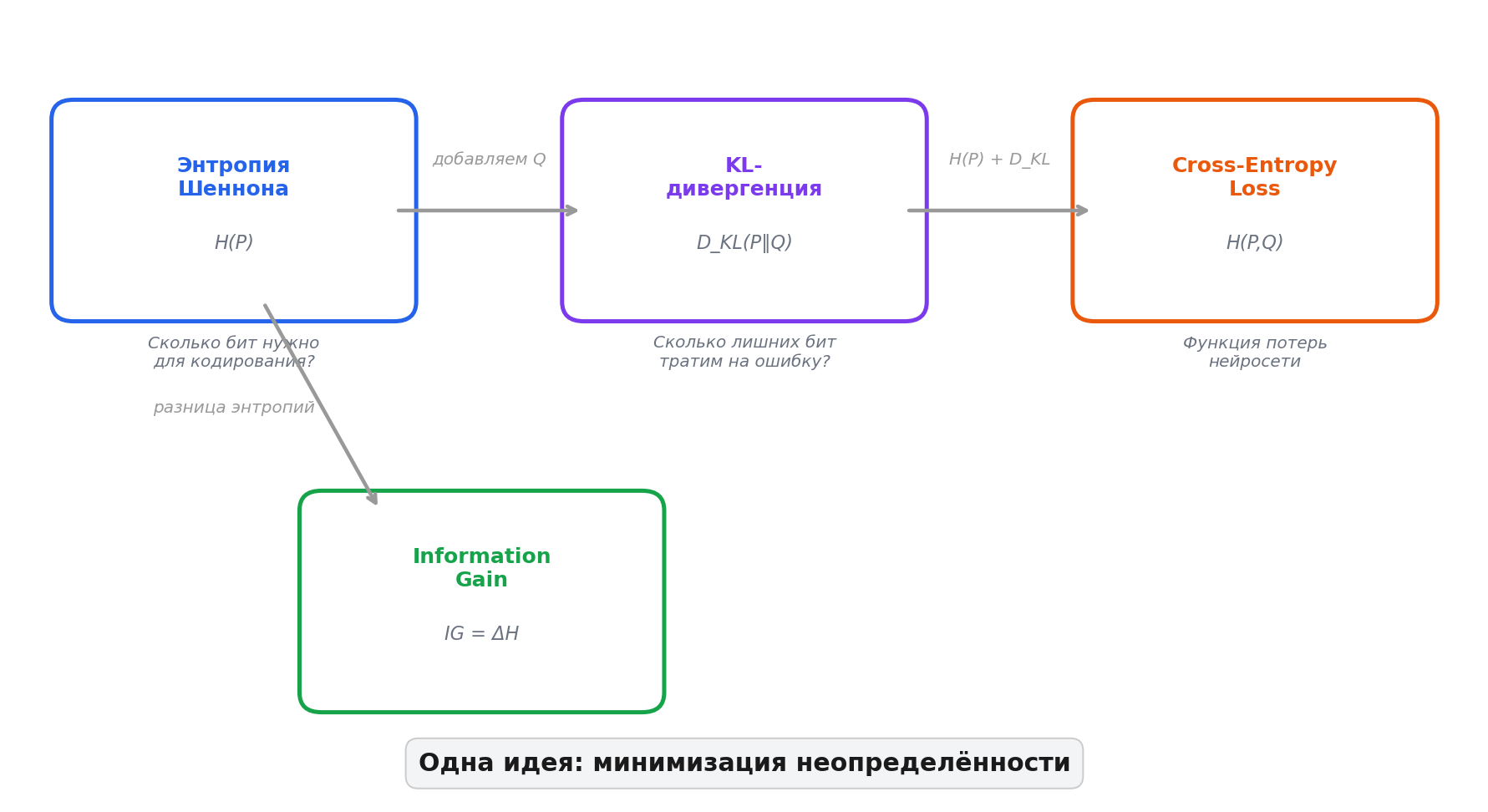
Когда дерево выбирает сплит с максимальным Information Gain — оно минимизирует энтропию.
Когда нейросеть минимизирует cross-entropy loss — она минимизирует KL-дивергенцию.
И то, и другое – это попытка сделать мир предсказуемее. Дерево делает это дискретными разрезами, а нейросеть непрерывной оптимизацией. Но математика одна и та же.
Почему это полезно знать
Понимание связи помогает диагностировать проблемы:
Высокий cross-entropy loss при хорошем AUC: модель правильно ранжирует объекты, но её вероятности врут. Она говорит «0.9» там, где на самом деле «0.6». AUC это не видит (он про ранжирование), а cross-entropy видит (он про расстояние до истинного распределения). Решение: калибровка (Platt scaling, isotonic regression).
Information Gain близок к нулю на всех признаках: ни один признак не снижает энтропию. У вас шум, а не данные. Или задача не решается деревьями. Или нужна feature engineering.
Энтропия целевой переменной близка к нулю: один класс доминирует (99% vs 1%). Энтропия бит — почти нет неопределённости, которую можно снижать. Дерево будет строить тривиальные сплиты, а accuracy будет 99% без модели. Это сигнал использовать другие метрики (precision, recall, MCC) и методы работы с дисбалансом.
Итого
Энтропия Шеннона — мера неопределённости: сколько бит нужно, чтобы закодировать исход.
Information Gain — это снижение энтропии при сплите. Деревья решений оптимизируют именно это.
KL-дивергенция — информационная стоимость ошибки: сколько лишних бит вы тратите, используя неправильную модель.
Cross-Entropy Loss — KL-дивергенция между реальностью и предсказаниями (при one-hot метках). Нейросети оптимизируют именно это.
Одна формула 1948 года. Три мира. Одна идея: мир неопределён, и мы хотим сделать его предсказуемее.