Бутстрап: единственный стат. тест, который вам нужен
Содержание
Всем привет! 👋 Сегодня мы разберем бутсрап. Его преимущества и недостатки. Очень часто вокруг себя, на конференциях или в частных тг-каналах вижу обсуждение различных статистических инструментов и почти никогда не слышу про бутстрап, хотя гарантирую, что после прочтения этой статьи при вопросе “как построить доверительный интервал для этой метрики?” вы сразу будете думать о нём, а не о каком-то хитром способе, как привести выборку к какому-то распределению и исследовать его. Итак, начнем.
Когда параметрических методов не хватает
Параметрические методы (например, t-тест) хорошо работают в определённых условиях: большая выборка, распределение, близкое к нормальному, и статистика, для которой есть аналитическая формула стандартной ошибки.
Проблема в том, что на практике эти условия выполняются реже, чем хотелось бы.
Ситуация 1: статистика, для которой нет формулы. t-тест даёт интервал для среднего. А если нужен интервал для медианы revenue per user? Для 95-го перцентиля времени загрузки? Для отношения revenue / sessions? Аналитических формул стандартных ошибок для этих статистик либо нет, либо они требуют допущений, которые не выполняются.
Ситуация 2: скошенные данные на реальных выборках. Формула предполагает, что выборочное среднее распределено симметрично. Центральная предельная теорема это гарантирует, но при достаточно большом . Для скошенных распределений (revenue, длительность сессий, суммы покупок) ЦПТ сходится медленно. При симметричный интервал систематически ошибается.
Ситуация 3: сложные метрики в A/B-тестах. Например, отношение двух величин, или разница медиан, или что-то составное. Дельта-метод даёт приближение, но формулы быстро становятся громоздкими. А для каждой новой метрики приходится выводить формулу заново.
Бутстрап решает все три ситуации одним и тем же алгоритмом. Ниже я покажу это на данных.
Идея в одном абзаце
У вас есть выборка . Вы хотите узнать распределение некоторой статистики — среднего, медианы, перцентиля, чего угодно.
Алгоритм:
- Из выборки берёте случайную подвыборку размера с возвращением — это бутстрап-выборка .
- Считаете статистику .
- Повторяете раз (обычно ).
- Получаете значений — это эмпирическое распределение вашей статистики.
Из этого распределения можно извлечь стандартную ошибку, доверительный интервал, p-value.
Визуально: что происходит
Вот конкретный пример. Выборка из 50 наблюдений, распределение скошено вправо (типичная картина для revenue). Мы хотим оценить неопределённость медианы.
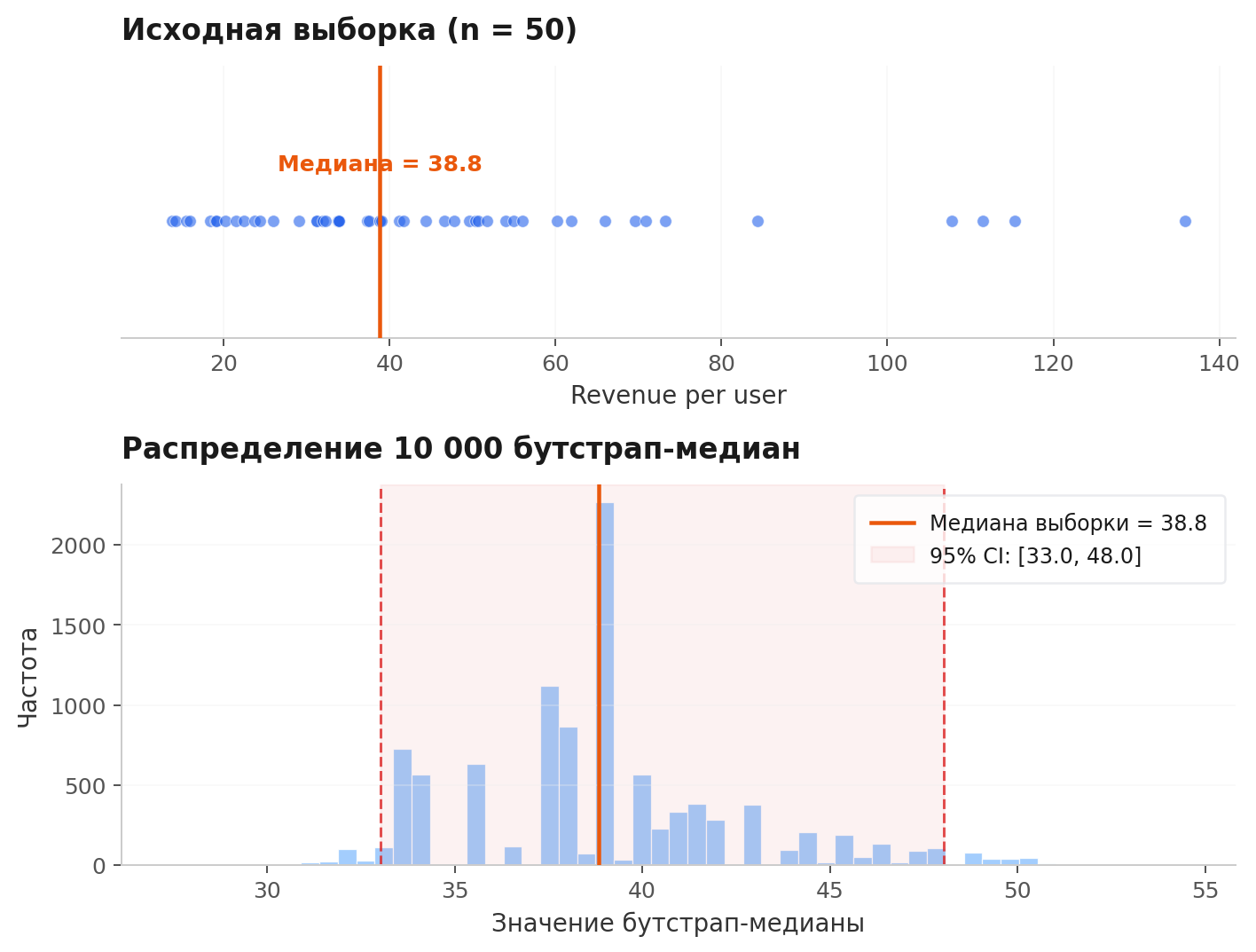
Верхний график визуализирует исходную выборку и её медиану. Нижний представляет собой гистограмму 10 000 бутстрап-медиан. Обратите внимание: распределение бутстрап-статистики не обязано быть нормальным. В данном случае оно скошено — и это важно. Бутстрап честно отражает эту скошенность, а симметричная формула нет.
Почему это работает: plug-in principle и Гливенко-Кантелли
Интуиция бутстрапа кажется подозрительной: мы семплируем из собственной выборки и делаем вид, что это новые данные. Почему это легитимно?
Ключ хранится plug-in principle. Идея простая: если мы не знаем истинное распределение , мы заменяем его эмпирическим распределением , которое присваивает каждому наблюдению вес .
Почему это работает? Потому что теорема Гливенко-Кантелли это нам гарантирует:
Эмпирическое распределение сходится к истинному равномерно и почти наверное. Не в одной точке, не в среднем, а по всей прямой одновременно. Это сильный результат.
Из этого следует: если , то и распределение статистики при семплировании из будет близко к её истинному распределению при семплировании из .
Формально: пусть — функционал от распределения (например, медиана). Бутстрап-оценка — это . Если функционал непрерывен (в подходящем смысле), то:
где — вероятность при семплировании из .
Бутстрап — это не магия. Это конструктивное следствие того, что эмпирическое распределение хорошо приближает истинное. Мы не генерируем новые данные. Мы используем структуру имеющихся данных, чтобы оценить вариабельность нашей статистики.
Доверительные интервалы: три метода
Имея бутстрап-значений статистики, мы можем построить доверительный интервал. Но “как?” вопрос не тривиальный. Существуют три основных подхода, и они дают разные результаты.
1. Перцентильный метод (Percentile)
Простейший вариант. Берём квантили бутстрап-распределения напрямую:
где — это -квантиль из бутстрап-значений.
Плюс: простота. Минус: не учитывает смещение оценки и может давать неправильное покрытие, если бутстрап-распределение несимметрично.
2. Нормальный метод (Normal)
Предполагаем, что бутстрап-распределение приблизительно нормальное:
где — стандартное отклонение бутстрап-оценок.
Плюс: использует исходную оценку , а не только бутстрап. Минус: предполагает симметрию, что для скошенных статистик (медиана, перцентили) не работает.
3. BCa — Bias-Corrected and Accelerated
Это метод, предложенный Эфроном, и на сегодня считающийся стандартом. Он корректирует два артефакта перцентильного метода:
- Bias correction () — поправка на систематическое смещение. Оценивается как доля бутстрап-значений, меньших исходной оценки:
- Acceleration () — поправка на скошенность. Оценивается через джекнайф (jackknife — метод, при котором мы по очереди выкидываем одно наблюдение из выборки и пересчитываем статистику на оставшихся , получая оценок; это показывает, насколько сильно каждое наблюдение влияет на результат):
где — статистика, вычисленная без -го наблюдения, а — среднее джекнайф-оценок.
Скорректированные квантили:
Если и , BCa вырождается в обычный перцентильный метод. Но на практике и почти никогда не равны нулю, и BCa даёт значительно лучшее покрытие.
Если вы используете бутстрап для чего-то серьёзнее учебного примера — используйте BCa. Вычислительная стоимость джекнайфа минимальна ( дополнительных вычислений статистики), а выигрыш в покрытии реальный.
Теперь давайте посмотрим на реальных примерах.
Эксперименты
Кейс 1: покрытие на скошенных данных
Вот конкретный эксперимент. Берём lognormal-распределение (, ), типичное распределение доходов. Строим 95% доверительный интервал для среднего тремя способами: t-интервал, перцентильный бутстрап и BCa-бутстрап. Повторяем 2 000 раз с новыми выборками и считаем, как часто интервал накрывает истинное среднее.
Если метод работает правильно, покрытие должно быть ≈ 95%.
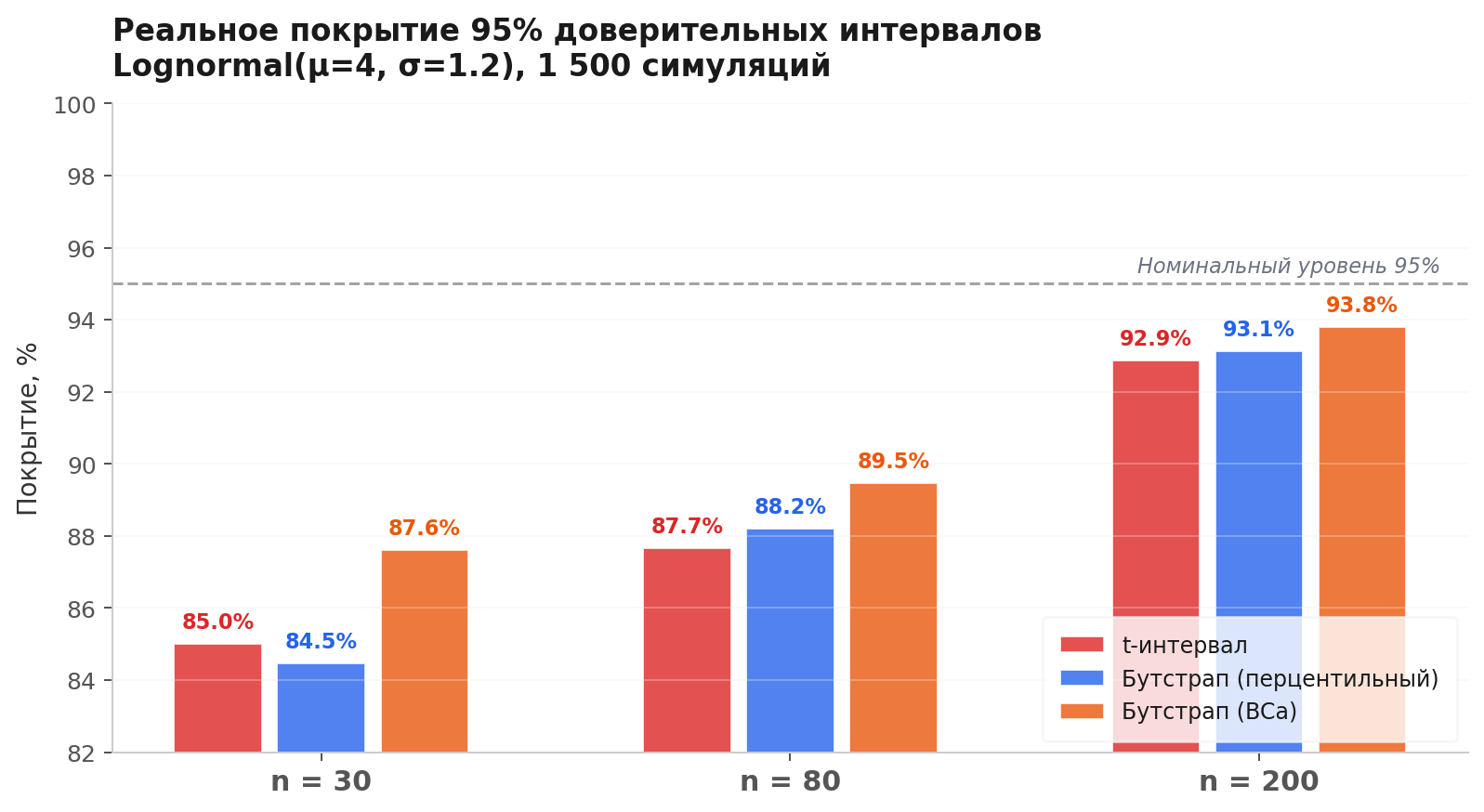
При t-интервал даёт покрытие ~85% вместо заявленных 95%. Каждый шестой интервал промахивается мимо истинного значения, хотя не должен. BCa-бутстрап на тех же данных держит ~88% — тоже не идеально, но ближе к цели. Разрыв сокращается с ростом : при t-интервал даёт 93%, BCa — 94%.
Почему t-интервал ошибается? Потому что он симметричен: . А распределение среднего для lognormal-данных при малых скошено вправо. Симметричный интервал занижает верхнюю границу и завышает нижнюю. Бутстрап не предполагает симметрию — он строит интервал из фактического распределения статистики.
Кейс 2: интервал для статистики без формулы
Вторым кейсом рассмотрим ситуацию, где параметрические методы просто не применимы.
У вас есть данные A/B-теста: для каждого пользователя revenue и число сессий. Метрика revenue per session на уровне группы: . Это ratio-метрика, и её стандартная ошибка не вычисляется простой формулой (можно через дельта-метод, но это отдельная история с допущениями).
Бутстрап решает задачу в три строки: семплируем пользователей, считаем ratio, повторяем.
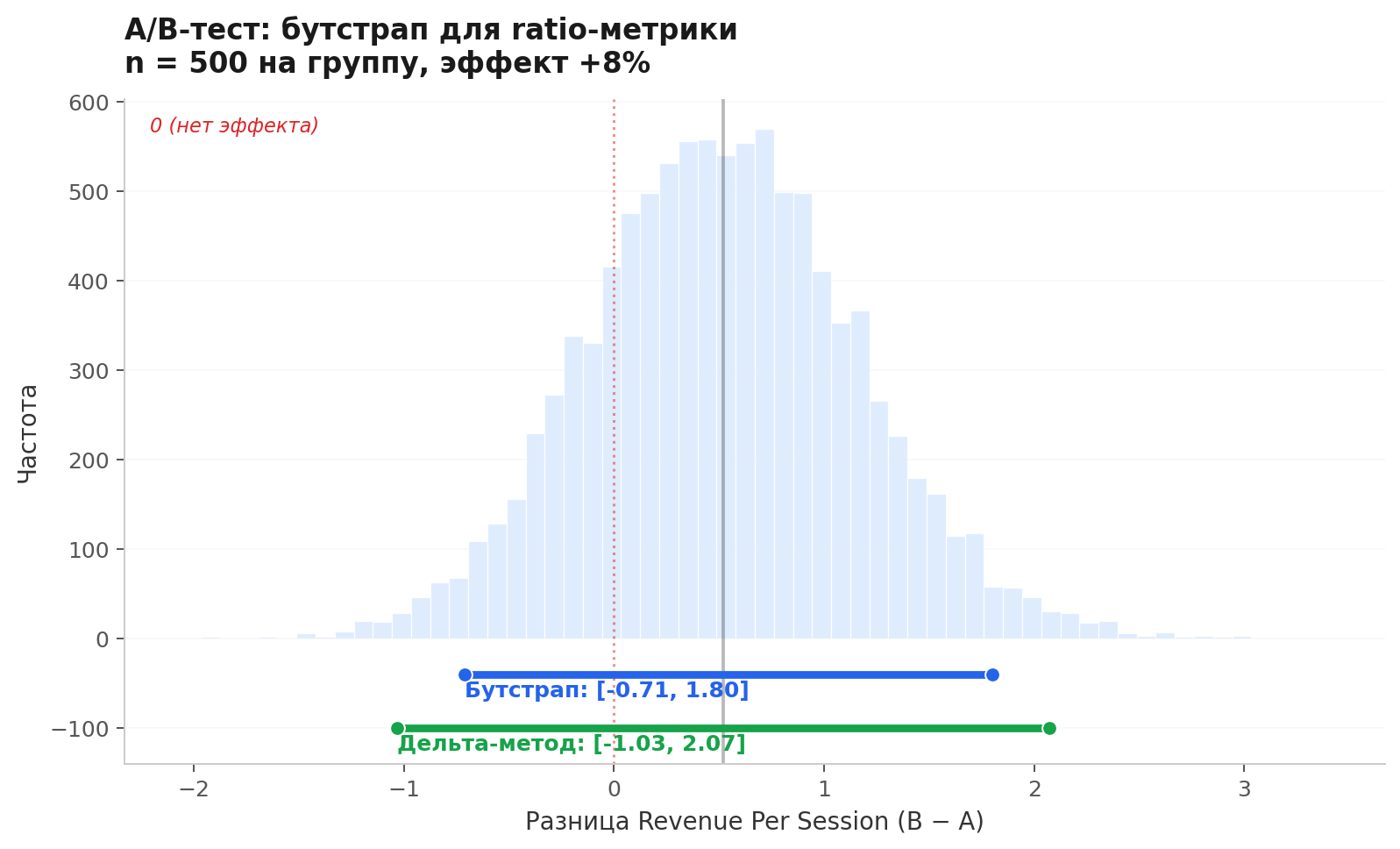
На графике — бутстрап-распределение разницы revenue per session между группами A и B. Интервал асимметричен, и это правильно, потому что ratio-метрики не обязаны быть симметричными. Симметричный интервал через дельта-метод наложен для сравнения, он занижает верхнюю границу.
Этот интервал невозможно получить t-тестом. t-тест работает с поюзерными значениями, но ratio на уровне группы — это не среднее поюзерных ratio. Это другая статистика, и бутстрап — самый прямой способ получить для неё доверительный интервал.
Где бутстрап ломается
Бутстрап — мощный инструмент, но не всесильный. Вот три ситуации, где он не работает или работает плохо.
1. Тяжёлые хвосты
Если данные из распределения с бесконечной дисперсией (например, Коши), функционалы, зависящие от хвостов, будут плохо оцениваться. Бутстрап-распределение среднего при выборке из Коши не стабилизируется — потому что среднее Коши не имеет конечного математического ожидания.
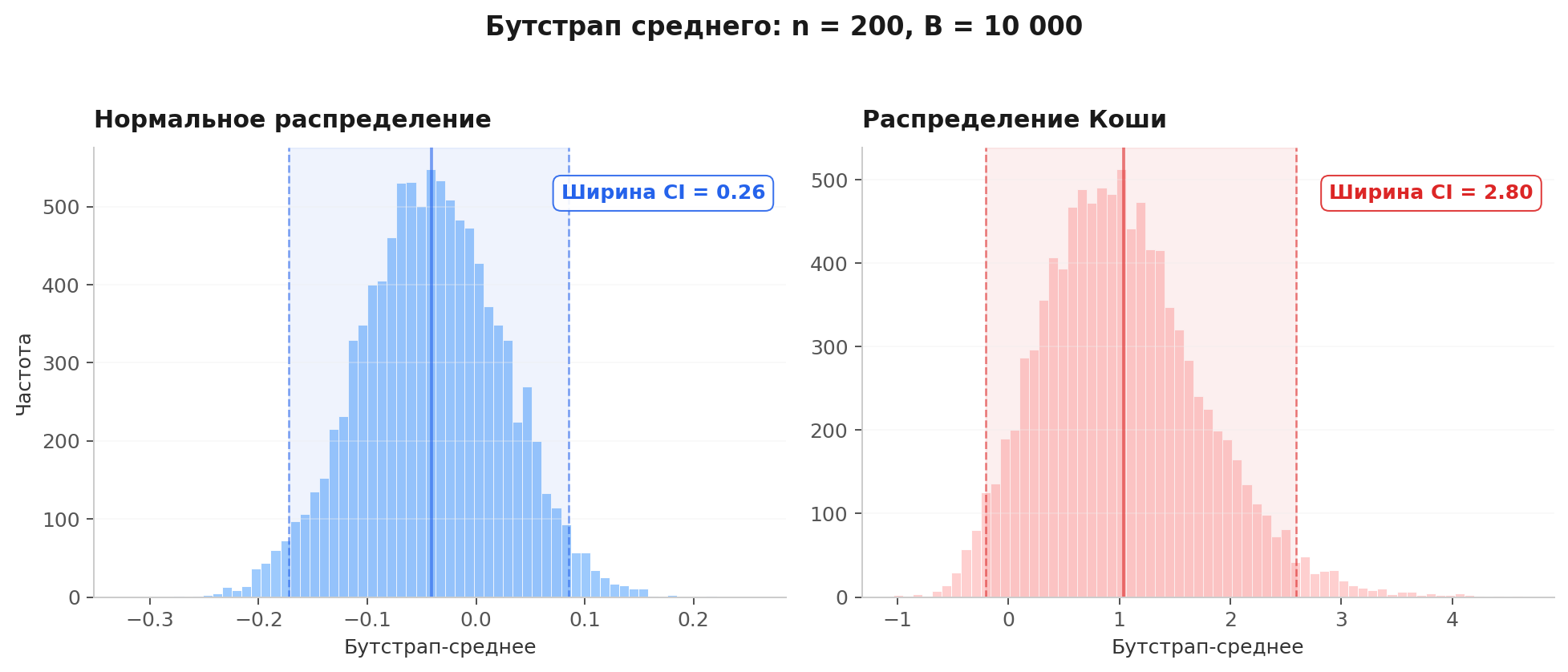
Слева бутстрап среднего для нормального распределения (). Стабильный колокол, узкий интервал. Справа то же для распределения Коши. Ширина интервала в 10 раз больше, и при каждом запуске результат будет другим.
На практике чистое Коши встречается редко, но тяжёлые хвосты постоянно: доходы пользователей, время сессий, суммы транзакций.
Решение: для тяжелохвостых данных используйте робастные статистики (медиану вместо среднего, trimmed mean) или проверяйте стабильность бутстрап-интервала при увеличении .
2. Очень малые выборки
При эмпирическое распределение является слишком грубой аппроксимацей истинного. Бутстрап-выборка из 10 наблюдений будет содержать в среднем уникальных значений (остальное дубликаты). Информации мало, и доверительные интервалы получаются ненадёжными.
Почему ? Вероятность, что конкретное наблюдение не попадёт в бутстрап-выборку: . Ожидаемое число уникальных: .
| Ожидаемое число уникальных | Доля | |
|---|---|---|
| 10 | 6.3 | 63% |
| 30 | 19.0 | 63% |
| 100 | 63.2 | 63% |
| 1000 | 632.1 | 63% |
Доля стабильна (), но при абсолютное число уникальных значений слишком мало.
3. Зависимые данные
Стандартный бутстрап предполагает, что наблюдения независимы. Если у вас временной ряд, семплирование с возвращением разрушает временну́ю структуру.
Решение: блочный бутстрап (block bootstrap): вместо отдельных наблюдений семплируются блоки последовательных значений. Длина блока представляет собой гиперпараметр, который нужно подбирать. Это отдельная тема, но знать о ней необходимо, чтобы не применять стандартный бутстрап к временным рядам.
Итого: козыри бутстрапа
Один алгоритм для любой статистики. Средние, медианы, перцентили, отношения, разности — бутстрап не требует выводить новую формулу для каждого случая. Это его главное практическое преимущество.
Честное покрытие на скошенных данных. Мы показали на симуляции: при на lognormal-данных t-интервал даёт покрытие 85% вместо заявленных 95%. BCa-бутстрап держит 88% — и разрыв с номиналом сокращается быстрее, чем у t-интервала.
Теоретический фундамент. Не эвристика, а следствие теоремы Гливенко-Кантелли — эмпирическое распределение сходится к истинному равномерно.
Используйте BCa. Если делаете бутстрап — используйте BCa-интервалы. Вычислительная стоимость минимальна (джекнайф — это дополнительных вычислений), а покрытие значительно лучше перцентильного метода.
Помните об ограничениях. Тяжёлые хвосты, малые выборки (), зависимые данные — три случая, когда стандартный бутстрап может подвести.