Selection bias в антифроде
Содержание
Всем привет! 👋 Сегодня предлагаю рассмотреть, как работать с антифрод системами. У них есть ряд классических проблем, которые хотелось бы разобрать.
У вас модель с AUC 0.99. Precision 0.95. Recall 0.92. На бумаге всё идеально. Вы деплоите в прод. Через месяц бизнес приходит и говорит: «Фрода стало больше». Как это возможно?
Так что давайте разберемся, почему антифрод это не обычная задача классификации, почему стандартные метрики на тестовой выборке врут, и что с этим делать.
Почему антифрод это не обычная классификация
В стандартной задаче классификации у вас есть размеченные данные: вот класс 0, вот класс 1. Обучили модель, протестировали на отложенной выборке, задеплоили. В антифроде всё сложнее по трём причинам.
Экстремальный дисбаланс. Фрод это обычно 0.1-1% транзакций. Модель, которая на всё говорит «легитимно», права в 99% случаев. Accuracy бессмысленна. Это мы уже разбирали в контексте других метрик, но тут проблема острее, чем где-либо.
Adversarial environment. Фродстеры адаптируются. Модель поймала паттерн, фродстеры сменили паттерн. Модель деградирует, но вы этого можете не заметить, потому что старые паттерны всё ещё ловятся, а новые ещё не набрали массу.
Feedback loop. И вот тут начинается самое интересное.
Проблема смещения данных
Это ключевая проблема антифрода, и именно она делает задачу принципиально отличной от, скажем, классификации изображений.
Как формируются данные для обучения? Модель v1 оценивает транзакцию. Подозрительная? Блокируем, отправляем на ручной ревью, размечаем как фрод или не фрод. Не подозрительная? Пропускаем. И вот тут проблема: мы никогда не узнаём, был ли это фрод.
То есть в обучающей выборке для модели v2 есть только те кейсы, которые модель v1 сочла подозрительными. Это классический selection bias: вы видите только то, что прошлая модель решила вам показать.
Представьте, что вы оцениваете качество охранника склада, но видите только тех, кого он задержал. Тех, кого он пропустил, вы не видите. И на основе данных о задержанных обучаете нового охранника. Новый будет хорош ровно в том, в чём был хорош старый. И слеп ровно в том, в чём был слеп старый.
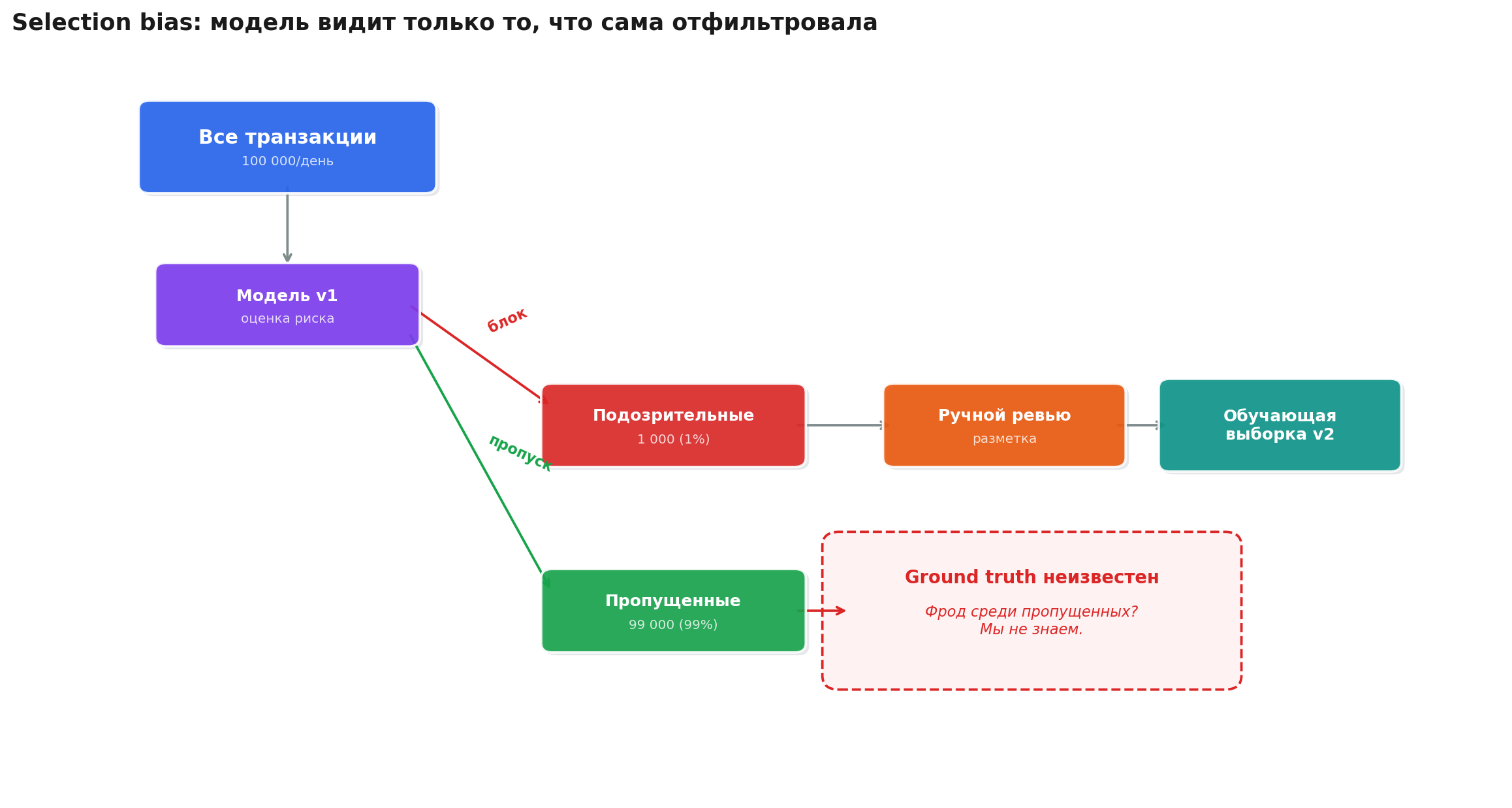
Эта проблема усиливается с каждой итерацией. Модель v2 обучена на смещённых данных от v1. Модель v3 обучена на смещённых данных от v2, которая уже была смещена. Каждое поколение модели наследует и усиливает слепые зоны предыдущего. В литературе это называют feedback loop, и в антифроде он особенно опасен, потому что фродстеры активно эксплуатируют именно слепые зоны модели.
Как работать на смещённых данных
Проблема понятна. Что делать?
Подход 1: рандомизированный пропуск (random passthrough)
Самый прямолинейный способ получить несмещённые данные. Вы специально пропускаете небольшой процент (0.1-1%) подозрительных транзакций без блокировки, чтобы узнать ground truth.
Да, это стоит денег. Реальный фрод пройдёт, и компания понесёт убытки. Но это единственный способ получить честную разметку для транзакций, которые модель считает фродом.
По сути это exploration в explore/exploit trade-off. Вы платите за информацию сейчас, чтобы модель работала лучше потом.
Важный нюанс: random passthrough нужно делать на уровне решений модели, а не на уровне всего трафика. Пропускать 1% всех транзакций бессмысленно (99% из них легитимны и так). Пропускать 1% тех, что модель хотела заблокировать, информативно.
Но есть важный момент. В некоторых доменах пропускать фрод дорого и опасно. Одно дело пропустить мошенническую покупку на 500 рублей, другое дело пропустить account takeover с выводом всех средств. Не везде можно позволить себе exploration за реальные деньги клиентов.
Что можно сделать в таких случаях:
- Ограничить passthrough по сумме. Пропускать только транзакции ниже определённого порога. Вы теряете информацию о крупном фроде, но не теряете крупные деньги.
- Использовать «мягкий» пропуск. Вместо полной блокировки и полного пропуска ввести промежуточное действие: дополнительная верификация (SMS-код, звонок). Пользователь проходит проверку, вы получаете сигнал о его легитимности, а реальный фродстер отваливается на этом шаге. Это даёт разметку без прямых потерь.
Подход 2: inverse propensity weighting
Если вы знаете вероятность того, что транзакция попала в ревью (propensity score), можно перевзвесить данные, чтобы скомпенсировать смещение. Идея из каузального вывода: транзакции, которые попали в ревью с маленькой вероятностью, получают больший вес при обучении.
Логика простая: если модель пропускала определённый тип транзакций с вероятностью 95%, а ревьюила с вероятностью 5%, то каждая отревьюированная транзакция этого типа получает вес 20 (1/0.05). Это компенсирует то, что мы видели только 5% таких транзакций.
Плюс: не требует пропускать фрод в прод.
Минус: если propensity score оценён неточно (а он всегда оценён неточно), веса могут быть нестабильными. Транзакция с propensity 0.001 получит вес 1000, что взорвёт обучение.
Подход 3: отложенная разметка
Не все виды фрода требуют мгновенной реакции. Таргет может созреть (то есть выявиться фрод). Можно пропустить транзакцию, подождать, и узнать правду: если через 60 дней пришёл chargeback, это был фрод.
Это даёт чистую, несмещённую разметку. Но с задержкой в месяцы. Работает для, например, фрода по карточками, но не работает для account takeover, где ущерб наносится мгновенно.
На практике системы комбинируют все три подхода: random passthrough для калибровки, IPW для коррекции обучающей выборки, и отложенную разметку для долгосрочной валидации.
Проблема оценки качества
Допустим, вы обучили модель. Как оценить, хорошая ли она? Стандартный подход (AUC/precision/recall на тестовой выборке) тут не работает. И вот почему.
Проблема 1: тестовая выборка тоже смещена
Если тестовая выборка сформирована тем же процессом, что и обучающая (а обычно так и есть), она содержит тот же selection bias. Модель показывает AUC 0.99 на данных, которые уже были отфильтрованы предыдущей моделью. Это как проверять охранника на тех же людях, которых он уже задерживал. Конечно, он их «поймает» снова.
Единственный способ получить честную оценку: тестировать на данных из random passthrough, где ground truth известен без смещения.
Проблема 2: precision и recall зависят от порога
В антифроде порог модели это бизнес-решение. Сколько легитимных пользователей вы готовы заблокировать?
Precision 0.95 при блокировке 0.5% транзакций и precision 0.70 при блокировке 3% транзакций это совершенно разные реальности. Первое значит: мы блокируем мало, но почти не ошибаемся. Второе: мы блокируем агрессивно, и треть заблокированных были невиновны.
Одна и та же модель, разные пороги, разные метрики. Без привязки к бизнес-контексту precision/recall сами по себе не информативны.
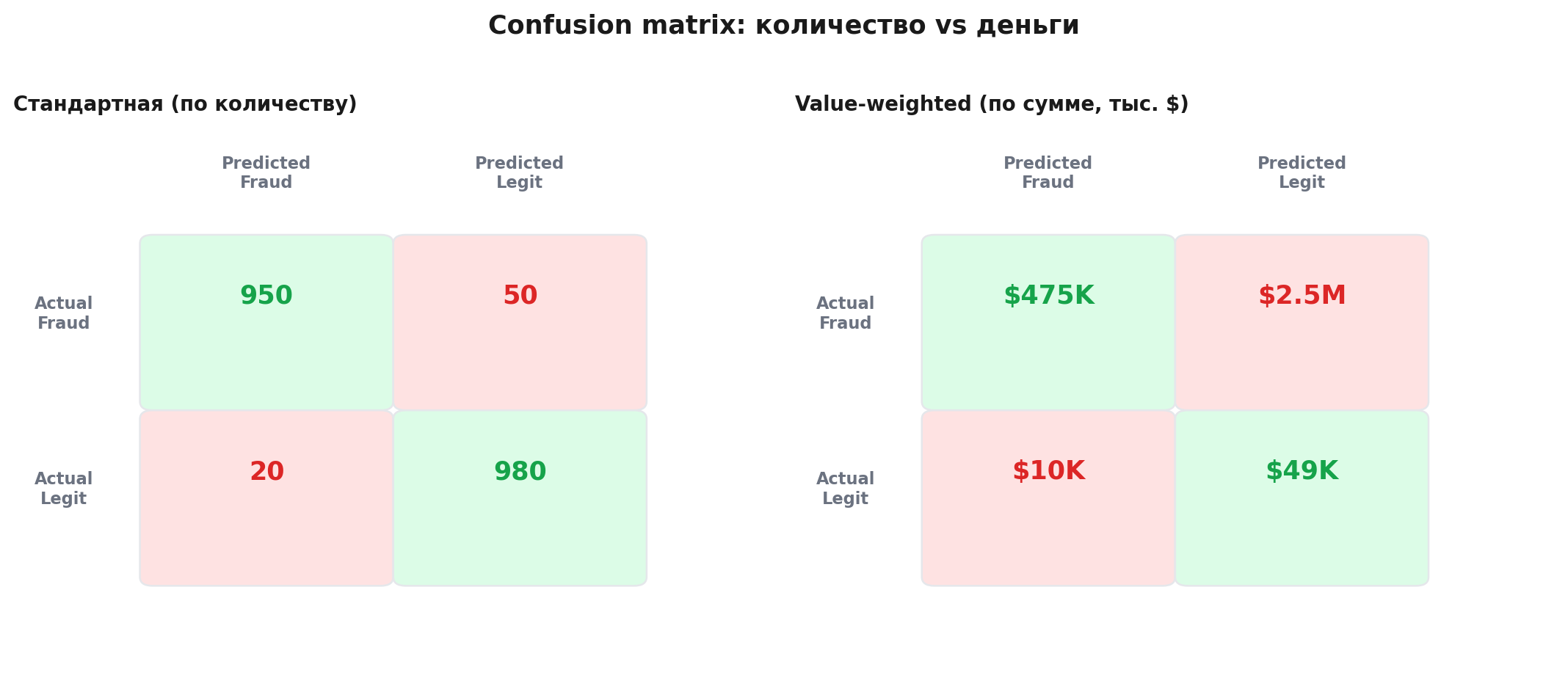
Проблема 3: метрики не учитывают стоимость ошибки
False negative на 500 рублей и false negative на 500 000 рублей это разные ошибки. Стандартный recall считает их одинаково. Но бизнесу не всё равно.
Нужна value-weighted метрика:
Не «какой процент фродов мы поймали», а «какой процент денег мы спасли».
Аналогично для false positive: блокировка пользователя с LTV 10 000 имеют разную цену. Стандартный precision этого не видит.
Как правильно оценивать
Правильная оценка антифрод-модели включает три компонента:
A/B-тест в проде с random passthrough. Единственный способ получить несмещённую оценку. Старая модель на одной группе, новая на другой, небольшой процент пропущенных транзакций для ground truth.
Value-weighted метрики. Не количество пойманных фродов, а сумма спасённых денег. Не количество заблокированных легитимных пользователей, а потерянный LTV.
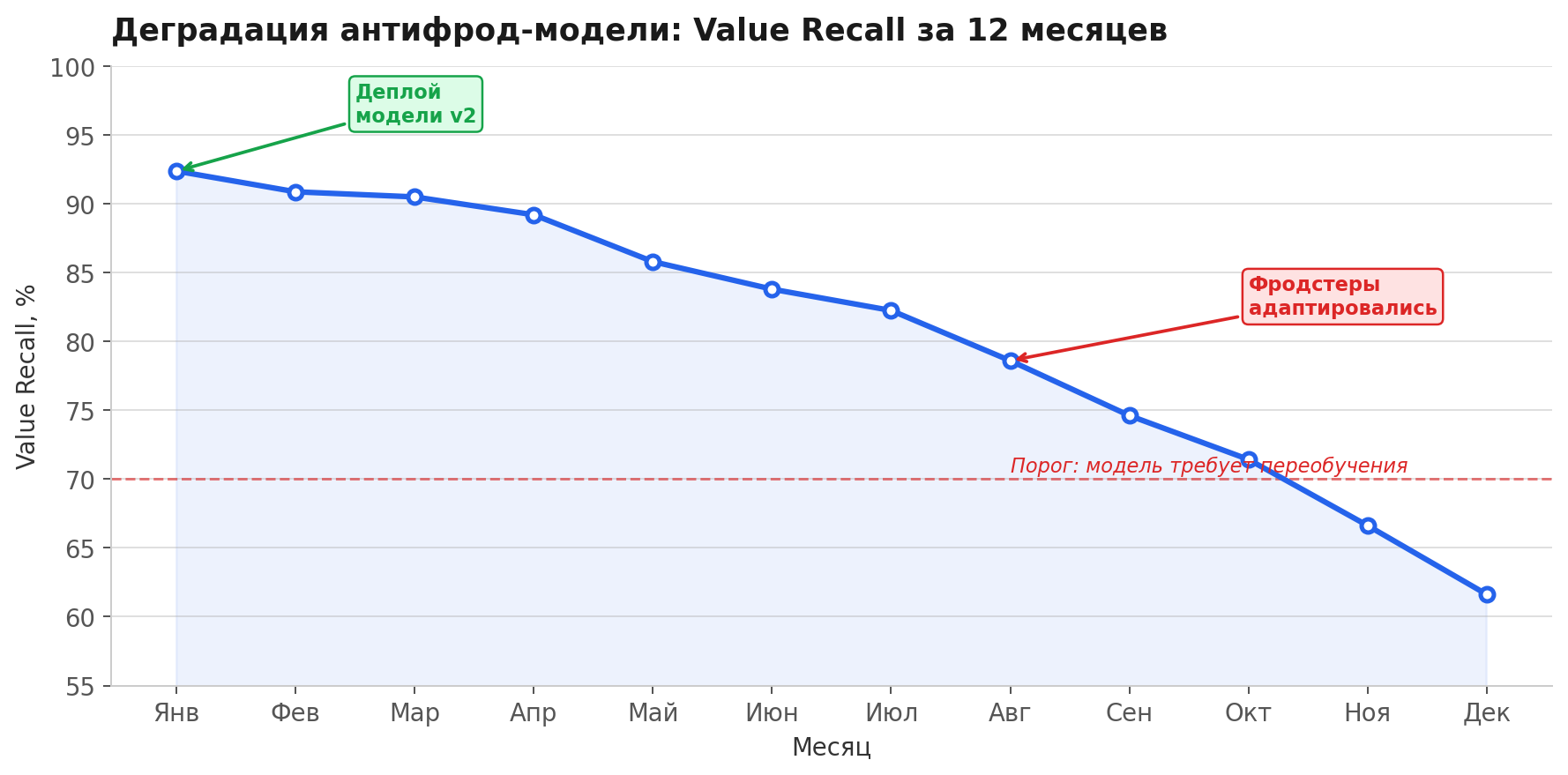
Мониторинг деградации. Антифрод-модель деградирует по определению, потому что противник адаптируется. Метрики нужно отслеживать не на дату деплоя, а в динамике. Если value recall падает на 2% в месяц, через полгода модель бесполезна.
Ключевые выводы
Антифрод это не задача классификации. Это задача принятия решений в условиях смещённых данных и адаптивного противника.
Selection bias это не баг, а архитектурная особенность. Каждое поколение модели наследует слепые зоны предыдущего. Без random passthrough или IPW вы обучаете модель на искажённой картине мира.
AUC на тестовой выборке не значит ничего. Тестовая выборка смещена тем же процессом, что и обучающая. Честная оценка возможна только в проде.
Считайте деньги, а не штуки. Value recall и value precision информативнее стандартных метрик на порядок.
Модель деградирует по определению. Фродстеры адаптируются. Мониторинг во времени важнее однократной оценки на дату деплоя.